|
Data Mining & Predictive Analytics |

|
Tom Khabaza |
|
Nine Laws of Data Mining by Tom Khabaza
This content was created during the first quarter of 2010 to publish the “Nine Laws of Data Mining”, which explain the reasons underlying the data mining process. If you prefer brevity, see my tweets: twitter.com/tomkhabaza. If you are a member of LinkedIn, see the “9 Laws of Data Mining” subgroup of the CRISP-DM group for a discussion forum. This page contains laws 1-4, with further laws on additional pages. The 9 Laws are also expressed as haikus here.
Data mining is the creation of new knowledge in natural or artificial form, by using business knowledge to discover and interpret patterns in data.
In its current form, data mining as a field of practise came into existence in the 1990s, aided by the emergence of data mining algorithms packaged within workbenches so as to be suitable for business analysts. Perhaps because of its origins in practice rather than in theory, relatively little attention has been paid to understanding the nature of the data mining process. The development of the CRISP-DM methodology in the late 1990s was a substantial step towards a standardised description of the process that had already been found successful and was (and is) followed by most practising data miners.
Although CRISP-DM describes how data mining is performed, it does not explain what data mining is or why the process has the properties that it does. In this paper I propose nine maxims or “laws” of data mining (most of which are well-known to practitioners), together with explanations where known. This provides the start of a theory to explain (and not merely describe) the data mining process.
It is not my purpose to criticise CRISP-DM; many of the concepts introduced by CRISP-DM are crucial to the understanding of data mining outlined here, and I also depend on CRISP-DM’s common terminology. This is merely the next step in the process that started with CRISP-DM.
——————————————————————————————————
1st Law of Data Mining – “Business Goals Law”: Business objectives are the origin of every data mining solution
This defines the field of data mining: data mining is concerned with solving business problems and achieving business goals. Data mining is not primarily a technology; it is a process, which has one or more business objectives at its heart. Without a business objective (whether or not this is articulated), there is no data mining.
Hence the maxim: “Data Mining is a Business Process”.
——————————————————————————————————
2nd Law of Data Mining – “Business Knowledge Law”:
This defines a crucial characteristic of the data mining process. A naive reading of CRISP-DM would see business knowledge used at the start of the process in defining goals, and at the end of the process in guiding deployment of results. This would be to miss a key property of the data mining process, that business knowledge has a central role in every step.
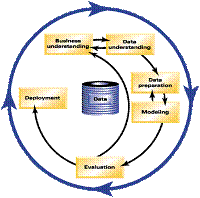
For convenience I use the CRISP-DM phases to illustrate: · Business understanding must be based on business knowledge, and so must the mapping of business objectives to data mining goals. (This mapping is also based on data knowledge data mining knowledge). · Data understanding uses business knowledge to understand which data is related to the business problem, and how it is related. · Data preparation means using business knowledge to shape the data so that the required business questions can be asked and answered. (For further detail see the 3rd Law – the Data Preparation law). · Modelling means using data mining algorithms to create predictive models and interpreting both the models and their behaviour in business terms – that is, understanding their business relevance. · Evaluation means understanding the business impact of using the models. · Deployment means putting the data mining results to work in a business process.
In summary, without business knowledge, not a single step of the data mining process can be effective; there are no “purely technical” steps. Business knowledge guides the process towards useful results, and enables the recognition of those results that are useful. Data mining is an iterative process, with business knowledge at its core, driving continual improvement of results.
The reason behind this can be explained in terms of the “chasm of representation” (an idea used by Alan Montgomery in data mining presentations of the 1990s). Montgomery pointed out that the business goals in data mining refer to the reality of the business, whereas investigation takes place at the level of data which is only a representation of that reality; there is a gap (or “chasm”) between what is represented in the data and what takes place in the real world. In data mining, business knowledge is used to bridge this gap; whatever is found in the data has significance only when interpreted using business knowledge, and anything missing from the data must be provided through business knowledge. Only business knowledge can bridge the gap, which is why it is central to every step of the data mining process.
——————————————————————————————————
3rd Law of Data Mining – “Data Preparation Law”: Data preparation is more than half of every data mining process
It is a well-known maxim of data mining that most of the effort in a data mining project is spent in data acquisition and preparation. Informal estimates vary from 50 to 80 percent. Naive explanations might be summarised as “data is difficult”, and moves to automate various parts of data acquisition, data cleaning, data transformation and data preparation are often viewed as attempts to mitigate this “problem”. While automation can be beneficial, there is a risk that proponents of this technology will believe that it can remove the large proportion of effort which goes into data preparation. This would be to misunderstand the reasons why data preparation is required in data mining.
The purpose of data preparation is to put the data into a form in which the data mining question can be asked, and to make it easier for the analytical techniques (such as data mining algorithms) to answer it. Every change to the data of any sort (including cleaning, large and small transformations, and augmentation) means a change to the problem space which the analysis must explore. The reason that data preparation is important, and forms such a large proportion of data mining effort, is that the data miner is deliberately manipulating the problem space to make it easier for their analytical techniques to find a solution.
There are two aspects to this “problem space shaping”. The first is putting the data into a form in which it can be analysed at all – for example, most data mining algorithms require data in a single table, with one record per example. The data miner knows this as a general parameter of what the algorithm can do, and therefore puts the data into a suitable format. The second aspect is making the data more informative with respect to the business problem – for example, certain derived fields or aggregates may be relevant to the data mining question; the data miner knows this through business knowledge and data knowledge. By including these fields in the data, the data miner manipulates the search space to make it possible or easier for their preferred techniques to find a solution.
It is therefore essential that data preparation is informed in detail by business knowledge, data knowledge and data mining knowledge. These aspects of data preparation cannot be automated in any simple way.
This law also explains the otherwise paradoxical observation that even after all the data acquisition, cleaning and organisation that goes into creating a data warehouse, data preparation is still crucial to, and more than half of, the data mining process. Furthermore, even after a major data preparation stage, further data preparation is often required during the iterative process of building useful models, as shown in the CRISP-DM diagram.
CRISP-DM Diagram ——————————————————————————————————
4th Law of Data Mining – “NFL-DM”: The right model for a given application can only be discovered by experiment or “There is No Free Lunch for the Data Miner”
It is an axiom of machine learning that, if we knew enough about a problem space, we could choose or design an algorithm to find optimal solutions in that problem space with maximal efficiency. Arguments for the superiority of one algorithm over others in data mining rest on the idea that data mining problem spaces have one particular set of properties, or that these properties can be discovered by analysis and built into the algorithm. However, these views arise from the erroneous idea that, in data mining, the data miner formulates the problem and the algorithm finds the solution. In fact, the data miner both formulates the problem and finds the solution – the algorithm is merely a tool which the data miner uses to assist with certain steps in this process.
There are 5 factors which contribute to the necessity for experiment in finding data mining solutions: 1. If the problem space were well-understood, the data mining process would not be needed – data mining is the process of searching for as yet unknown connections. 2. For a given application, there is not only one problem space; different models may be used to solve different parts of the problem, and the way in which the problem is decomposed is itself often the result of data mining and not known before the process begins. 3. The data miner manipulates, or “shapes”, the problem space by data preparation, so that the grounds for evaluating a model are constantly shifting. 4. There is no technical measure of value for a predictive model (see 8th law). 5. The business objective itself undergoes revision and development during the data mining process, so that the appropriate data mining goals may change completely.
This last point, the ongoing development of business objectives during data mining, is implied by CRISP-DM but is often missed. It is widely known that CRISP-DM is not a “waterfall” process in which each phase is completed before the next begins. In fact, any CRISP-DM phase can continue throughout the project, and this is as true for Business Understanding as it is for any other phase. The business objective is not simply given at the start, it evolves throughout the process. This may be why some data miners are willing to start projects without a clear business objective – they know that business objectives are also a result of the process, and not a static given.
Wolpert’s “No Free Lunch” (NFL) theorem, as applied to machine learning, states that no one bias (as embodied in an algorithm) will be better than any other when averaged across all possible problems (datasets). This is because, if we consider all possible problems, their solutions are evenly distributed, so that an algorithm (or bias) which is advantageous for one subset will be disadvantageous for another. This is strikingly similar to what all data miners know, that no one algorithm is the right choice for every problem. Yet the problems or datasets tackled by data mining are anything but random, and most unlikely to be evenly distributed across the space of all possible problems – they represent a very biased sample, so why should the conclusions of NFL apply? The answer relates to the factors given above: because problem spaces are initially unknown, because multiple problem spaces may relate to each data mining goal, because problem spaces may be manipulated by data preparation, because models cannot be evaluated by technical means, and because the business problem itself may evolve. For all these reasons, data mining problem spaces are developed by the data mining process, and subject to constant change during the process, so that the conditions under which the algorithms operate mimic a random selection of datasets and Wopert’s NFL theorem therefore applies. There is no free lunch for the data miner.
This describes the data mining process in general. However, there may well be cases where the ground is already “well-trodden” – the business goals are stable, the data and its pre-processing are stable, an acceptable algorithm or algorithms and their
Many thanks to Chris Thornton of Sussex University for his help in formulating NFL-DM.
—————————————————————————————————— Click here for part 2 of this article. Click here for the conclusion of this article. ——————————————————————————————————
Copyright (c) Tom Khabaza 2010. |